Mythos System Card
SANITY.IO
I somehow managed to miss of one of the biggest news stories in last week’s edition, the release of Anthropics’s Mythos model. Or more correctly, its non-release!
The latest model from Anthropic is so powerful they haven’t formally released it yet. During model evaluation they determined that its ability to find exploits was so significant that they are initially only making it available to select organisations via project Glasswing. For a quick overview of this story, I’d recommend taking a look at Simon Willison’s blog post.
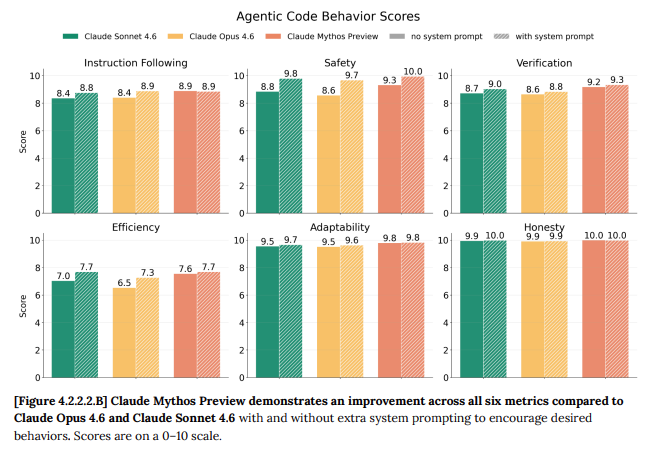
While the model’s ability to find zero days (vulnerabilities that no-one has yet discovered) grabbed most of the headlines, as well as the story about it escaping containment and emailing a research who was eating a sandwich on a park bench, digging into the system card reveals that its capability represents a huge leap forwards.
| Benchmark | Claude Mythos | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | — | 80.6% |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% | 54.2% |
| SWE-bench Multilingual | 87.3% | 77.8% | — | — |
| SWE-bench Multimodal | 59.0% | 27.1% | — | — |
| Terminal-Bench 2.0 | 82.0% | 65.4% | 75.1% | 68.5% |
| GPQA Diamond | 94.5% | 91.3% | 92.8% | 94.3% |
| MMMLU | 92.7% | 91.1% | — | 92.6–93.6% |
| USAMO | 97.6% | 42.3% | 95.2% | 74.4% |
| GraphWalks BFS 256K–1M | 80.0% | 38.7% | 21.4% | — |
| HLE (no tools) | 56.8% | 40.0% | 39.8% | 44.4% |
| HLE (with tools) | 64.7% | 53.1% | 52.1% | 51.4% |
| CharXiv (no tools) | 86.1% | 61.5% | — | — |
| CharXiv (with tools) | 93.2% | 78.9% | — | — |
An increase of 15-20% on SWE-Bench and Terminal-Bench is astonishing. I don’t think we’ve seen such a leap forward in model capability since GPT-4.
I do wonder when these models will be powerful enough to start reasoning about software on a system-level? i.e. undertaking architecture-level decisions and shaping a system accordingly. If this does happen, perhaps none of us will ever look at code again?
For the past while I’ve been unsure whether AI will gain the skills required to autonomously build complex software systems without any human engineering input, or at least that this is a number of years off. Given the leap that Mythos represents, this could happen sooner than I was thinking.
The peril of laziness lost
DTRACE.ORG
This is an excellent and highly quotable blog post about the perils of giving LLMs / AI Agents oo much latitude.
Bryan starts by introducing Larry Wall’s concept of the lazy developer, who is motivated to minimise effort an energy expenditure. This, mixed with impatience (anticipating future needs and write code against them) and hubris (writing code they are proud of and others will admire), drives lazy developers towards creating elegant abstractions.
We undertake the hard intellectual work of developing these abstractions in part because we are optimizing the hypothetical time of our future selves, even if at the expense of our current one
However, LLMs possess none of these qualities:
The problem is that LLMs inherently lack the virtue of laziness. Work costs nothing to an LLM.
As a result, LLMs, left unchecked, will make systems larger, not better.
Anthropic Downgraded Cache TTL on March 6th
GITHUB.COM
Just last week I included a link to a GitHub issue that claimed Claude Code was now unusable due to silent changes in behaviour. Here’s another one, this time pointing to a configuration change that has a significant cost impact.
LLMs use prompt caching as a way to optimise performance. With long sessions, the context can become quite lengthy, with new messages appended to a growing ‘conversation’. Prompt caching involves storing the intermediate activations (model state) from earlier sessions in order that they can be re-used. This allows teh LLM to essentially pick-up the conversation where it left off, rather than re-playing it on each invocation.
The user who raised this issue spotted that the caching behaviour changed a few weeks back, from a 1 hour cache to just 5 minutes. The end results is more frequent cache misses which increase user costs.
The reversion to 5-minute TTL has caused a 20–32% increase in cache creation costs
Anthropic, and other model providers, are moving at an incredible pace and as a result, communication of important changes to users is something they are often skipping. User growth is their primary goal!
Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All
QWEN.AI
Once again, open-weight models are (almost) keeping pace with the commercial closed models. Qwen has released a new mixture-of-experts model that is specifically designed for agentic coding tasks. It has strong scores on SWE-Bench (fixing open source issues), close to the frontier models, but lags behind a little on Terminal Bench (agentic tasks). It also drew a better Pelican Riding a Bike than Opus 4.7!
I am quite certain we’ll see prices increase at some point, as companies like Anthropic and OpenAI move from a subsidised battle for market-share to a more sustainable long-term model. It’s good to see that models which can run on commodity hardware are not far behind and will likely be a good alternative when that time comes.
Codex for (almost) everything
OPENAI.COM
I’ve been using Claude Code for many months now, however, I don’t use it for coding all that much - I tend to favour GitHub Copilot (with Claude models), due to its IDE integration. For me, Claude Code is my general purpose agent, and I use it daily … probably hourly. Whether it is for simple administrative tasks (e.g. resizing a bench of emails, PDF processing etc), or building more complex agentic solutions, e.g. my running coach, it is an indispensable part of my life now.
We’ve been talking about AI agents for a few years now, but the Claude Code creators discovered the right form-factor, and built the first tool that genuinely deserves that name. Its access to tools, file-system, ability to write and execute code, have made it a highly versatile tool. Unfortunately, unless you are quite a technically minded user, it is also quite unsafe.
The success that Claude Code has found as a universal agent hasn’t gone unnoticed. Professional agents for non-technical users could be one of the most important product categories of all time. This blog post from OpenAI is basically playing catch-up.
Notably there isn’t any discussion here about safety and security!