An Empirical 100 Trillion Token Study with OpenRouter
OPENROUTER.AI
A 100,000,000,000,000 token study? AI loves big numbers! Joking aside, this is actually really interesting stuff.
OpenRouter is a recent start-up that provides a unified gateway for accessing Large Language Models, making it easier to track usage, billing and avoid vendor lock-in. As a result, the traffic following through their gateway provides some fascinating insights into how people are using this technology (or at least those who are customers of this specific service).
There is some interesting analysis of which models are most popular, the types of task people are using these models for and more. I’ll leave you to read at your leisure, but I do want to call out some specifics that related to AI-augmented software development.
Programming has rapidly risen from around 10% to 50% of the overall usage over the past 7 months:
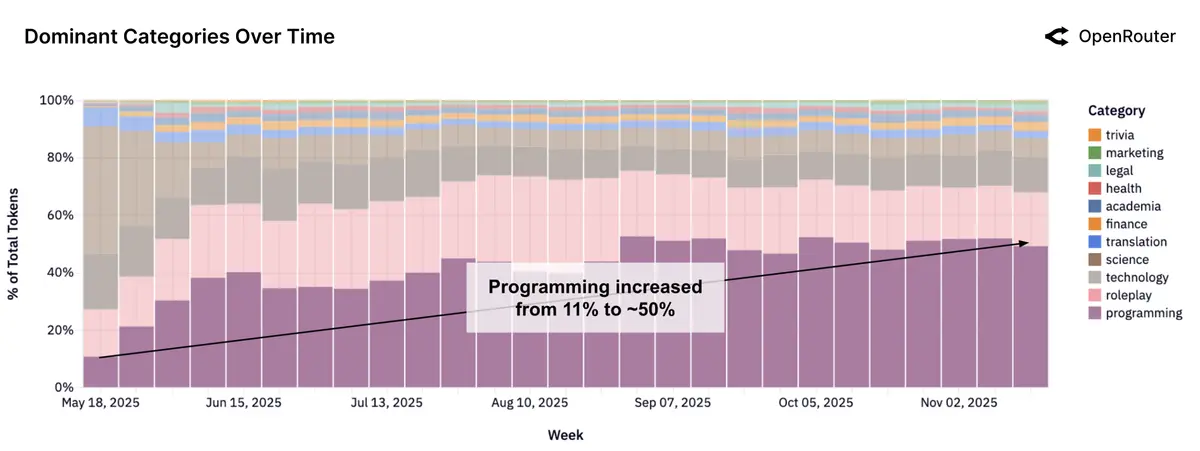
“This trend reflects a shift from exploratory or conversational use toward applied tasks such as code generation, debugging, and data scripting”
As we’ve seen in all the latest model releases (GPT 5.1 Codex max, Claude Opus 4.5, Gemini 3.0), software development is a primary use case that AI labs are heavily optimising for. The shift from AI as a ‘pair programmer’ to a fully autonomous agent has seen a massive increase in overall adoption.
Anthropic’s Claude model has been dominant throughout, rarely dipping beneath a consistent 60% market share. And from what I’ve heard and experiences, the recent Opus 4.5 release is a leading model, and we can expect this dominance to persist.
AWS unveils frontier agents
ABOUTAMAZON.COM
Earlier this week AWS held their re:Invent conference amid the glitz of Las Vegas. As you can imagine much of the event was AI themed, with an emphasis on building AI agents.
There were some announcements around their AI coding products, including Kiro, which was launched four months ago, plus two new agents (one for security, the other for DevOps). I don’t think any of these announcements will generate much interest, AWS are a long way behind. However, Kiro’s approach, with a greater emphasis on up-front planning, does give it a modest differentiator.
Writing a good CLAUDE.md
HUMANLAYER.DEV
AI Agents are trained on a vast amount of code and as a result, the patterns in the code they emit roughly follows the averages in that training dataset. For your project, you might want the agent to follow specific coding standards, adopt specific patterns, or use certain APIs. The CLAUDE.md of AGENTS.md file is a way to provide this project-specific context.
However, as with most things LLM-related, there isn’t a standard for these files. They are plain text, and how people write and structure them is the product of guesswork and iteration.
There is a lot of hype out there, with people sharing overly complex CLAUDE.md files and claiming amazing results. This blog post isn’t that. It is a simple, straightforward and sensible guide to how you approach this rather ambiguous task. I especially like the point about ‘progressive disclosure’.